병렬처리
2개 이상의 프로세스로 SQL을 처리하는 것
병렬처리의 실행
병렬처리 실행 유도 힌트 : PARALLEL
SELECT * /*+ PARALLEL(A 2) */
FROM TABLE A* PARALLEL(테이블_alias 병렬_프로세스_갯수)
* PARALLEL은 FULL 힌트와 함께 사용하는 것이 좋음. 옵티마이저의 판단으로 인덱스 스캔이 동작하면 PARALLEL이 적용되지 않음.
오라클 병렬처리 실행 과정
- 지정된 갯수의 프로세스들이 테이블 풀스캔 (Producer)
- 지정된 갯수의 프로세스들이 데이터를 전달받아 Group by, Order by, Join 등을 처리 (Consumer)
- 이 때, 각 프로세스가 담당하는 데이터는 서로 배타적 (연관 없음)
- 데이터를 하나로 합침 (Query Coordinator)
* group by, order by와 같이 데이터를 전달받아 재분배(재작업)하는 과정이 발생하면, 힌트로 지정한 프로세스 X 2 만큼의 프로세스가 실행됨.

ORDER BY가 있는 경우 병렬처리 예시
SELECT * /*+ PARALLEL(2) */
FROM TABLE A
ORDER BY NO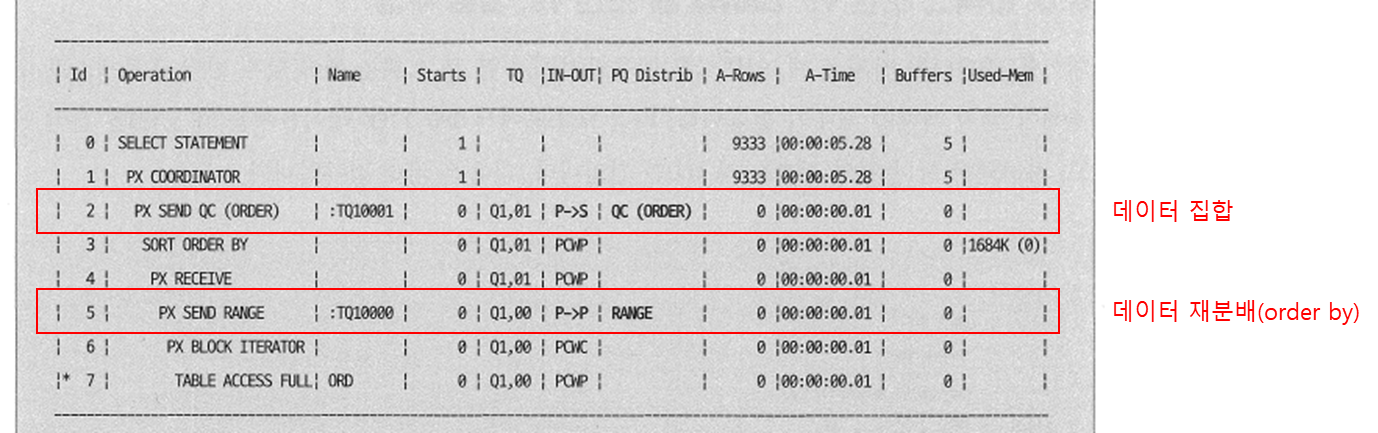
파티션이 되어있는 테이블에서 병렬처리가 큰 효과를 발휘함.
특정 칼럼(들)을 기준으로 테이블 또는 인덱스를 파티셔닝할 때 사용하는 분배 방식
1. 병렬 처리에서는 "해시조인"을 가장 많이 사용함. ( 병렬처리는 보통 대용량 처리, 테이블 풀스캔을 하기 때문)
2. 조인 작업을 수행하기 위해 데이터 쌍을 만드는 작업을 파티션 와이즈 조인(partition wise join)이라고 함.
- 파티션된 테이블 간의 조인에서, 파티션끼리만 조인되어 데이터의 재분배가 일어나지 않으면 풀 파티션 와이즈 조인이라고 함
- 한쪽만 파티션 된 테이블과 조인하는 경우, 한쪽에서만 데이터의 재분배가 일어나는 경우, 부분 파티션 와이즈 조인이라고 함.
- 양쪽 테이블에서 모두 데이터의 재분배가 일어나는 경우, 다이내믹 파티션 와이즈 조인이라고 함.
3. 데이터 재분배 방식 ( P -> P)
- RANGE
- order by 또는 sort group by를 병렬로 처리할 때 사용된다. 정렬 작업을 맡은 두 번째 서버 집합의 프로세스마다 처리 범위(예를 들어, A~G, H~M, N~S, T~Z)를 지정하고 나서, 데이터를 읽는 첫 번째 서버 집합이 두 번째 서버 집합의 정해진 프로세스에게 “정렬 키 값에 따라” 분배하는 방식이다.
- HASH
- 조인이나 hash group by를 병렬로 처리할 때 사용된다. 조인 키나 group by 키 값을 해시 함수에 적용하고 리턴된 값에 따라 데이터를 분배하는 방식
- BROADCAST
- QC 또는 첫 번째 서버 집합에 속한 프로세스들이 각각 읽은 데이터를 두 번째 서버 집합에 속한 “모든” 병렬 프로세스에게 전송하는 방식
- 병렬 조인에서 크기가 매우 작은 테이블이 있을 때 사용
- KEY
- 특정 칼럼(들)을 기준으로 테이블 또는 인덱스를 파티셔닝할 때 사용하는 분배 방식

pq_distribute 힌트
데이터의 재분배 방식을 유도하는 힌트

병렬 처리와 NL 조인
- 조회 조건이 한 쪽 테이블에 집중되어 있어, 한 테이블에서 조회되는 건수가 적고, 인덱스 키가 조인 조건인 경우
- 한 쪽 테이블만 병렬로 데이터를 읽어 각 프로세스가 NL 조인을 수행하게 하는 방식.
- NL조인으로 병렬처리를 할 때는 PARALLEL_INDEX 힌트를 사용
SELECT /*+ PARALLEL_INDEX(TABLE_A INDEX_A 2)
INDEX(TABLE_A INDEX_A)
USE_NL(TABLE_B) */
FROM TABLE_A
JOIN TABLE_B
ON TABLE_A.ID = TABLE_B.ID* PARALLEL_INDEX(테이블 인덱스 병렬처리갯수) : 테이블과, 인덱스, 병렬 프로세스 갯수를 지정
* INDEX(테이블 인덱스) : 테이블에서 인덱스 지정
* USE_NL : NL 조인 유도
* PARALLEL_INDEX 힌트는 INDEX 힌트와 함께 사용한 것이 좋음. 옵티마이저의 판단으로 PARALLEL_INDEX 힌트가 적용되지 않을 수 있기 때문
* PARALLEL_INDEX 힌트에서 언급된 인덱스가 파티션 인덱스가 아니라면 Fast Full Scan에서만 동작함
참고
박찬권, 오라클 에센셜 튜닝
https://docs.oracle.com/cd/E11882_01/server.112/e25523/parallel002.htm#i1010979
How Parallel Execution Works
The number of parallel execution servers associated with a single operation is known as the degree of parallelism (DOP). Parallel execution is designed to effectively use multiple CPUs. the Oracle Database parallel execution framework enables you to either
docs.oracle.com
https://dataonair.or.kr/db-tech-reference/d-guide/sql/?mod=document&uid=374
배치 프로그램 튜닝
1. 배치 프로그램 튜닝 개요 가. 배치 프로그램이란 일반적으로 배치(Batch) 프로그램이라 하면, 일련의 작업들을 하나의 작업 단위로 묶어 연속적으로 일괄 처리하는 것을 말한다. 온라인 프로그
dataonair.or.kr
'DB > SQL' 카테고리의 다른 글
| [Oracle] I/O (0) | 2022.04.05 |
|---|---|
| MYSQL Partition 파티션 키와 테이블 (0) | 2021.12.08 |
| MySQL 튜닝 : 대량 데이터 수정/삽입 시 인덱스 제거 (0) | 2021.10.11 |
| MySQL 튜닝 : 적합한 인덱스 생성하기 (0) | 2021.10.11 |
| MySQL 튜닝 : 인라인 뷰 데이터 줄이기 (0) | 2021.10.10 |